Written by
daweibayu
on
on
Java 数据结构
主要数据结构关系图
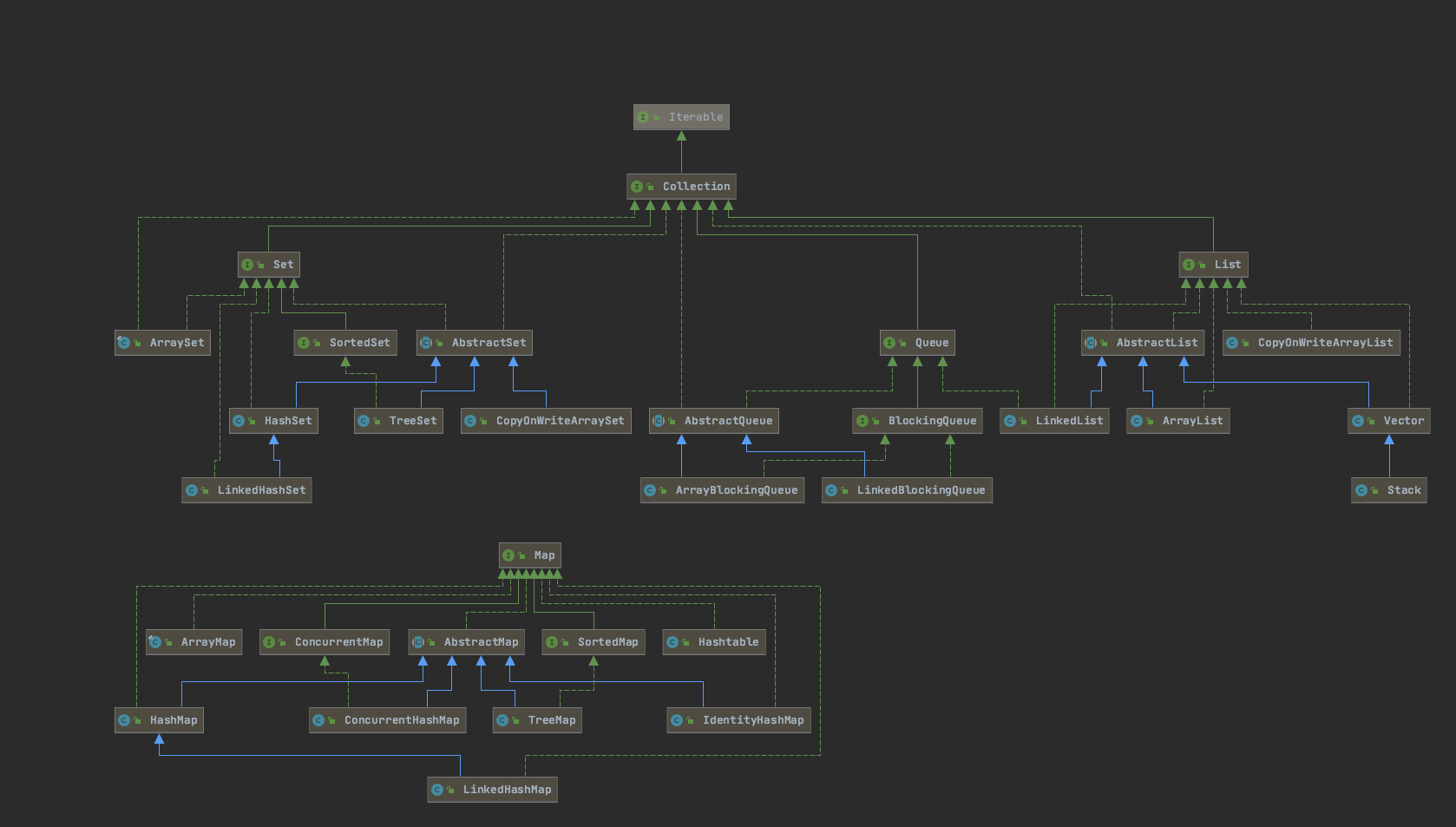
线程安全数据结构
Vector
- 通过函数上添加 synchronized 关键字保持线程安全
Stack
- 通过函数上添加 synchronized 关键字保持线程安全,Vector 子类
Hashtable
- 通过函数上添加 synchronized 关键字保持线程安全
CopyOnWriteArrayList
- ReentrantLock
- get 不限制,set、add 等写操作通过 ReentrantLock
- 适合用在读取和遍历多的场景下,并不适合写并发高的场景(数组拷贝耗时)
- 适用数据集不是特别大的情况(数组拷贝耗时)
- 不能保证数据强一致性,比如一边写一边读,读的是旧数组中的值
ConcurrentHashMap
- CAS & synchronized 保证线程安全
-
和JDK 1.8 HashMap 的数据结构一致,数组 & (链表 红黑树)
ConcurrentHashSet
BlockingQueue,ArrayBlockingQueue; LinkedBlockingQueue; PriorityBlockingQueue
AtomicInteger
- Atomic* 系列的线程安全均是通过 Unsafe 实现
线程不安全数据结构
ArrayList
LinkedList
- 双端队列,非线程安全
- transient Node
first; - transient Node
last;
Unsafe: 单例,final(不能继承),通过调用系统 native 函数操作底层资源 Atomic*系列和一些其他数据结构,通过 Unsafe#CAS 实现线程安全
SparseArray
- SparseArray 内部使用双数组,分别存储 Key 和 Value,Key 是 int[],用于查找 Value 对应的 Index,来定位数据在 Value 中的位置。
- 使用二分查找来定位 Key 数组中对应值的位置,所以 Key 数组是有序的。
- 使用数组就要面临删除数据时数据搬移的问题,所以引入了 DELETE 标记。
插入的时候为了给新数据腾位置,需要执行一个时间复杂度度为 O(n)的搬移操作,这是无法避免的 查找操作,时间复杂度可以做到 O(logn)
SparseBooleanArray、SparseLongArray、SparseIntArray 与 SparseArray 区别
- SparseArray 中的 value 数组为 private Object[] mValues;
- 而SparseBooleanArray 为 private boolean[] mValues;
- SparseLongArray 为 private long[] mValues;
ArrayMap 与 SparseArray 区别
都是通过 binarySearchHashes 查找 key
public final class ArrayMap<K, V> implements Map<K, V>
public class SparseArray<E> implements Cloneable
ArrayMap -> public V get(Object key)
ArrayMap -> public V put(K key, V value)
SparseArray -> public E get(int key)
SparseArray -> public void put(int key, E value)
实际 ArrayMap 中 的 key 也是计算完 hashcode 然后存入 int 数组的
int[] mHashes;
Object[] mArray;