on
【转载】Kotlin | 协程Flow数据流
转自 知乎 - 闲暇君,仅为防丢
Flow介绍
Flow 是 google 官方提供的一套基于 kotlin 协程的响应式编程模型,它与 RxJava 的使用类似,但相比之下 Flow 使用起来更简单,另外 Flow 作用在协程内,可以与协程的生命周期绑定,当协程取消时,Flow 也会被取消,避免了内存泄漏风险。
我们知道协程是轻量级的线程,本质上协程、线程都是服务于并发场景下,其中协程是协作式任务,线程是抢占式任务。默认协程用来处理实时性不高的数据,请求到结果后整个协程就结束了,即它是一锤子买卖。
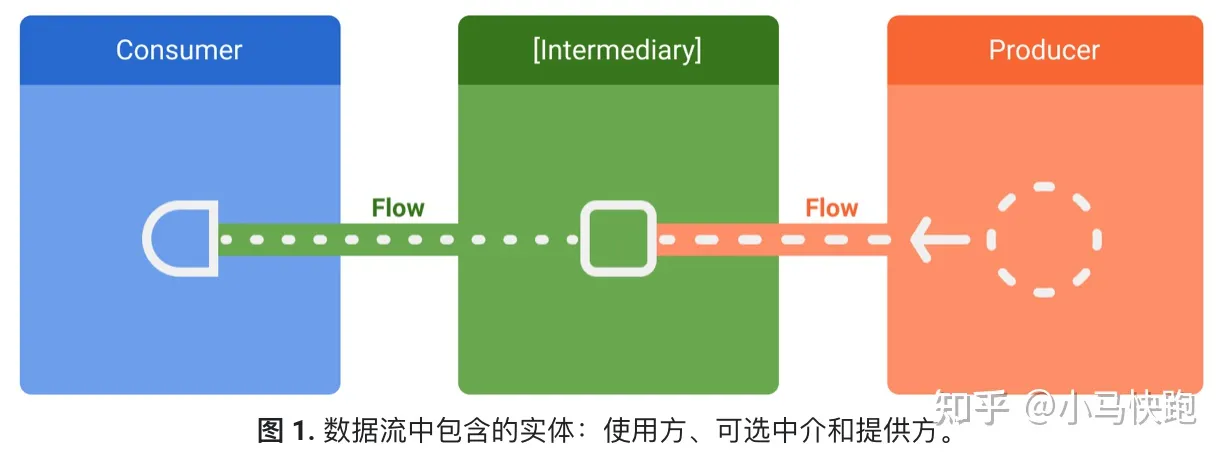
而 Flow 数据流可以按顺序发送多个值,官方对数据流三个成员的定义:
提供方会生成添加到数据流中的数据。通过协程,数据流还可以异步生成数据。
中介(可选),修改发送到数据流的值,或修正数据流本身。
使用方:使用或接收数据流中的值。
使用举例
举个Flow简单例子:
flow {
log("send hello")
emit("hello") //发送数据
log("send world")
emit("world") //发送数据
}.flowOn(Dispatchers.IO)
.onEmpty { log("onEmpty") }
.onStart { log("onStart") }
.onEach { log("onEach: $it") }
.onCompletion { log("onCompletion") }
.catch { exception -> exception.message?.let { log(it) } }
.collect {
//接收数据流
log("collect: $it")
}
执行结果:
2021-09-27 19:51:54.433 7240-7240/ E/TTT: onStart
2021-09-27 19:51:54.439 7240-7325/ E/TTT: send hello
2021-09-27 19:51:54.440 7240-7325/ E/TTT: send world
2021-09-27 19:51:54.451 7240-7240/ E/TTT: onEach: hello
2021-09-27 19:51:54.451 7240-7240/ E/TTT: collect:hello
2021-09-27 19:51:54.452 7240-7240/ E/TTT: onEach: world
2021-09-27 19:51:54.452 7240-7240/ E/TTT: collect:world
2021-09-27 19:51:54.453 7240-7240/ E/TTT: onCompletion
flow{} 为上游数据提供方,并通过 emit() 发送一个或多个数据,当发送多个数据时,数据流整体是有序的,即先发送先接收;另外发送的数据必须来自同一个协程内,不允许来自多个 CoroutineContext,所以默认不能在 flow{} 中创建新协程或通过 withContext() 切换协程。如需切换上游的CoroutineContext,可以通过 flowOn() 进行切换。
collect{}为下游数据使用方,collect是一个扩展函数,且是一个非阻塞式挂起函数(使用suspend修饰),所以Flow只能在kotlin协程中使用。
其他操作符可以认为都是服务于整个数据流的,包括对上游数据处理、异常处理等。
常用操作符
创建操作符
flow:创建Flow的操作符。 flowof:构造一组数据的Flow进行发送。 asFlow:将其他数据转换成Flow,一般是集合向Flow的转换,如listOf(1,2,3).asFlow()。 callbackFlow:将基于回调的 API 转换为Flow数据流
回调操作符
onStart:上游flow{}开始发送数据之前执行 onCompletion:flow数据流取消或者结束时执行 onEach:上游向下游发送数据之前调用,每一个上游数据发送后都会经过onEach() onEmpty:当流完成却没有发出任何元素时执行。如emptyFlow().onEmpty {} onSubscription:SharedFlow 专用操作符,建立订阅之后回调。和onStart的区别:因为SharedFlow是热流,因此如果在onStart发送数据,下游可能接收不到,因为提前执行了。
变换操作符
map:对上游发送的数据进行变换,collect最后接收的是变换之后的值 mapLatest:类似于collectLatest,当emit发送新值,会取消掉map上一次转换还未完成的值。 mapNotNull:仅发送map之后不为空的值。 transform:对发出的值进行变换 。不同于map的是,经过transform之后可以重新发送数据,甚至发送多个数据,因为transform内部又重新构建了flow。 transformLatest:类似于mapLatest,当有新值发送时,会取消掉之前还未转换完成的值。 transformWhile:返回值是一个Boolean,当为true时会继续往下执行;反之为false,本次发送的流程会中断。 asSharedFlow:MutableStateFlow 转换为 StateFlow ,即从可变状态变成不可变状态。 asStateFlow:MutableSharedFlow 转换为 SharedFlow ,即从可变状态变成不可变状态。 receiveAsFlow:Channel 转换为Flow ,上游与下游是一对一的关系。如果有多个下游观察者,可能会轮流收到值。 consumeAsFlow:Channel 转换为Flow ,有多个下游观察者时会crash。 withIndex:将数据包装成IndexedValue类型,内部包含了当前数据的Index。 scan(initial: R, operation: suspend (accumulator: R, value: T) -> R):把initial初始值和每一步的操作结果发送出去。 produceIn:转换为Channel的 ReceiveChannel runningFold(initial, operation: (accumulator: R, value: T) -> R):initial值与前面的流共同计算后返回一个新流,将每步的结果发送出去。 runningReduce*:返回一个新流,将每步的结果发送出去,默认没有initial值。 shareIn:flow 转化为 SharedFlow,后面会详细介绍。 stateIn:flow转化为StateFlow,后面会详细介绍。
过滤操作符
filter:筛选符合条件的值,返回true继续往下执行。 filterNot:与filter相反,筛选不符合条件的值,返回false继续往下执行。 filterNotNull:筛选不为空的值。 filterInstance:筛选对应类型的值,如.filterIsInstance()用来过滤String类型的值 drop:drop(count: Int)参数为Int类型,意为丢弃掉前count个值。 dropWhile:找到第一个不满足条件的值,返回其和其后所有的值。 take:与drop()相反,意为取前n个值。 takeWhile:与dropWhile()相反,找到第一个不满足条件的值,返回其前面所有的值。 debounce:debounce(timeoutMillis: Long)指定时间内只接收最新的值,其他的过滤掉。 sample:sample(periodMillis: Long)在指定周期内,获取最新发出的值。如:
flow {
repeat(10) {
emit(it)
delay(110)
}
}.sample(200)
执行结果:1, 3, 5, 7, 9
distinctUntilChangedBy:判断两个连续值是否重复,可以设置是否丢弃重复值。 distinctUntilChanged:若连续两个值相同,则跳过后面的值。
组合操作符
combine:组合两个Flow流最新发出的数据,直到两个流都结束为止。扩展:在kotlinx-coroutines-core-jvm中的FlowKt中,可以将更多的flow结合起来返回一个Flow,典型应用场景:多个筛选条件选中后,展示符合条件的数据。如果后续某个筛选条件发生了改变,只需要通过发生改变的Flow的flow.value = newValue重新发送,combine就会自动构建出新的Flow,这样UI层会接收到新的变化条件进行刷新即可。 combineTransform: combine + transform操作 merge:listOf(flow1, flow2).merge(),多个流合并为一个流。 flattenConcat:以顺序方式将给定的流展开为单个流 。示例如下:
flow {
emit(flowOf(1, 2,))
emit(flowOf(3,4))
} .flattenConcat().collect { value->
print(value)
}
// 执行结果:1 2 3 4 flattenMerge:作用和 flattenConcat 一样,但是可以设置并发收集流的数量。 flatMapContact:相当于 map + flattenConcat , 通过 map 转成一个流,在通过 flattenConcat发送。 flatMapLatest:当有新值发送时,会取消掉之前还未转换完成的值。 flatMapMerge:相当于map + flattenMerge ,参数concurrency: Int 来限制并发数。 zip:组合两个Flow流最新发出的数据,上游流在同一协程中顺序收集,没有任何缓冲。不同于combine的是,当其中一个流结束时,另外的Flow也会调用cancel,生成的流完成。
lifecycleScope.launch {
val flow = flowOf(1, 2, 3).onEach { delay(50) }
val flow2 = flowOf("a", "b", "c", "d").onEach { delay(150) }
val startTime = System.currentTimeMillis() // 记录开始的时间
flow.zip(flow2) { i, s -> i.toString() + s }.collect {
// Will print "1a 2b 3c"
log("$it 耗时 ${System.currentTimeMillis() - startTime} ms")
}
}
执行结果(flow已经执行完,所以flow2中的d被cancel了):
2022-05-20 /org.ninetripods.mq.study E/TTT: 1a 耗时 156 ms 2022-05-20 /org.ninetripods.mq.study E/TTT: 2b 耗时 307 ms 2022-05-20 /org.ninetripods.mq.study E/TTT: 3c 耗时 459 ms 如果换做combine,执行结果如下(组合的是最新发出的数据):
2022-05-20 /org.ninetripods.mq.study E/TTT: 2a 耗时 156 ms 2022-05-20 /org.ninetripods.mq.study E/TTT: 3a 耗时 159 ms 2022-05-20 /org.ninetripods.mq.study E/TTT: 3b 耗时 311 ms 2022-05-20 /org.ninetripods.mq.study E/TTT: 3c 耗时 466 ms 2022-05-20 /org.ninetripods.mq.study E/TTT: 3d 耗时 620 ms 注:上面combine多次执行的结果可能不一致,但每次组合的是最新发出的数据
功能性操作符
cancellable:判断当前协程是否被取消 ,如果已取消,则抛出异常 catch:对此操作符之前的流发生的异常进行捕获,对此操作符之后的流无影响。当发生异常时,默认collect{}中lambda将不会再执行。当然,可以自行通过emit()继续发送。 retry:流发生异常时的重试机制。如果是无限重试,直接调用retry()默认方法即可,retry()最终调用的也是retryWhen()方法。
public fun <T> Flow<T>.retry(
retries: Int = Int.MAX_VALUE, //指定重试次数
predicate: (Throwable) -> Boolean = { true } //返回true且满足retries次数要求,继续重试;false停止重试
): Flow<T> {
require(retries > 0) { "Expected positive amount of retries, but had $retries" }
return retryWhen { cause, attempt -> predicate(cause) && attempt < retries }
}
retryWhen:流发生异常时的重试机制。
public fun <T> Flow<T>.retryWhen(predicate: suspend FlowCollector<T>.(cause: Throwable, attempt: Long) -> Boolean): Flow<T> = { ...... }
有条件的进行重试 ,lambda 中有两个参数: cause是 异常原因,attempt是当前重试的位置,lambda返回true时继续重试; 反之停止重试。
buffer:流执行总时间就是所有运算符执行时间之和。如果上下游运算符都比较耗时,可以考虑使用buffer()优化,该运算符会在执行期间为流创建一个单独的协程。
public fun
flowOf("A", "B", "C")
.onEach { println("1$it") }
.collect { println("2$it") }
//上述代码在协程Q中按以下顺序执行:
Q : -->-- [1A] -- [2A] -- [1B] -- [2B] -- [1C] -- [2C] -->--
此时,如果onEach()、collect()中的运算时间都比较长的话,那么总时间就是所有运算符执行时间之和。buffer运算符会在执行期间为流创建一个单独的协程,如下所示:
flowOf("A", "B", "C")
.onEach { println("1$it") }
.buffer() // <--------------- buffer between onEach and collect
.collect { println("2$it") }
上述代码将在两个协程中执行,其中buffer()以上还是在协程P中执行,而buffer()下面的collect()会在协程Q中执行,数据通过Channel进行传递,从而减少了执行的总时间。
P : -->-- [1A] -- [1B] -- [1C] ---------->-- // flowOf(...).onEach { ... }
|
| channel // buffer()
V
Q : -->---------- [2A] -- [2B] -- [2C] -->-- // collect
conflate:仅保留最新值, 内部实现是 buffer(CONFLATED) flowOn:flowOn 会更改上游数据流的 CoroutineContext,且只会影响flowOn之前(或之上)的任何中间运算符。下游数据流(晚于 flowOn 的中间运算符和使用方)不会受到影响。如果有多个 flowOn 运算符,每个运算符都会更改当前位置的上游数据流。
末端操作符
collect:数据收集操作符,默认的flow是冷流,即当执行collect时,上游才会被触发执行。 collectIndexed:带下标的收集操作,如collectIndexed{ index, value -> }。 collectLatest:与collect的区别:当新值从上游发出时,如果上个收集还未完成,会取消上个值得收集操作。 toCollection、toList、toSet:将flow{}结果转化为集合。 注:还有很多操作符没有列出来~
冷流 vs 热流
flow{}会创建一个数据流,并且这个数据流默认是冷流。除了冷流,还有对应的热流,下面是冷流和热流的区别:
冷流:当执行订阅的时候,上游发布者才开始发射数据流。订阅者与发布者是一一对应的关系,即当存在多个订阅者时,每个新的订阅者都会重新收到完整的数据。 热流:不管是否被订阅,上游发布者都会发送数据流到内存中。订阅者与发布者是一对多的关系,当上游发送数据时,多个订阅者都会收到消息。 来验证一下flow{}创建的是冷流:

起始状态
界面如上图所示,定义了2个订阅者,首先构建数据流:
var sendNum = 0
val mSimpleFlow = flow {
sendNum++
emit("sendValue:$sendNum")
}.flowOn(Dispatchers.IO)
以及两个订阅者:
mBtnContent1.setOnClickListener {
lifecycleScope.launch {
mSimpleFlow.collect {
mTvSend.text = it
mBtnContent1.text = it
}
}
}
mBtnContent2.setOnClickListener {
lifecycleScope.launch {
mSimpleFlow.collect {
mTvSend.text = it
mBtnContent2.text = it
}
}
}
当点击订阅者1的按钮时,flow{}中发送了sendValue1,执行结果:
 sendLeftBtn
sendLeftBtn
此时继续点击右边的订阅者2,flow{}中发送了sendValue2,执行结果:
 sendRightBtn
sendRightBtn
可以看到两个订阅者是互相不干扰的,都是单独与上游flow{}进行数据传递的,即冷流,另外,flow{}可以通过stateIn/shareIn将其转换为StateFlow/SharedFlow热流。
SharedFlow
我们知道flow{}构建的是冷流,而SharedFlow(共享Flow)默认是热流,发送器与收集器是一对多的关系。
public fun <T> MutableSharedFlow(
replay: Int = 0,
extraBufferCapacity: Int = 0,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): MutableSharedFlow<T>
replay:重播给新订阅者时缓存数据的个数,默认是0。当新订阅者collect时,会先尝试获取上游replay个数据,为0时则不会获取之前的数据。replay缓存是针对后续所有的订阅者准备的。 extraBufferCapacity:除了replay外,缓冲值的数量。当有剩余的缓冲区空间时,Emit不挂起(可选,不能为负,默认为零) 。extraBufferCapacity是为上游快速发射器及下游慢速收集器这种场景提供缓冲的,个人觉得有点类似于线程池中的存储队列。这里注意一点,replay保存的是最新值,而extraBufferCapacity保存的是最先发送的一个或多个值。 onBufferOverflow:配置缓冲区溢出的操作(可选,默认为SUSPEND,暂停尝试发出值),可选值有:SUSPEND-暂停发送、DROP_OLDEST-丢弃队列中最老的、DROP_LATEST-丢弃队列中最新的。 关于replay与extraBufferCapacity 的不同,可以参考 MutableSharedFlow 有点复杂这篇文章。
shareIn将普通flow转化为SharedFlow 普通flow{}可以通过shareIn将普通数据流转换成SharedFlow
public fun <T> Flow<T>.shareIn(
scope: CoroutineScope,
started: SharingStarted,
replay: Int = 0
): SharedFlow<T>
scope:协程作用域范围
started:控制共享的开始、结束策略。一共有三种,分别为Eagerly、Lazily、WhileSubscribed。
1、SharingStarted.Eagerly, //Eagerly:马上开始,在scope作用域结束时终止
2、SharingStarted.Lazily, //Lazily:当订阅者出现时开始,在scope作用域结束时终止
3、SharingStarted.WhileSubscribed(stopTimeoutMillis: Long = 0,replayExpirationMillis: Long = Long.MAX_VALUE)
其中stopTimeoutMillis:表示最后一个订阅者结束订阅与停止上游流的时间差,默认值为0(立即停止上游流)
replayExpirationMillis:数据重播的超时时间。
replay:重播给新订阅者的数量
举例:
//ViewModel中 普通flow通过shareIn转化为SharedFlow
val flowConvertSharedFlow by lazy {
flow {
emit("1、flow")
emit("2、convert")
emit("3、SharedFlow")
}.shareIn(
viewModelScope, //协程作用域范围
SharingStarted.Eagerly, //立即开始
replay = 3 //重播给新订阅者的数量
).onStart { log("onStart") }
}
//Activity中
mBtnConvertF.setOnClickListener {
val builder: StringBuilder = StringBuilder()
lifecycleScope.launch {
mFlowModel.flowConvertSharedFlow.collect {
log(it)
builder.append(it).append("\n")
mTvConvertF.text = builder.toString()
}
}
}
执行结果:
2021-10-09 15:11:08.340 4549-4549/ E/TTT: onStart 2021-10-09 15:11:08.340 4549-4549/ E/TTT: 1、flow 2021-10-09 15:11:08.341 4549-4549/ E/TTT: 2、convert 2021-10-09 15:11:08.341 4549-4549/ E/TTT: 3、SharedFlow
StateFlow
StateFlow特点:
StateFlow可以认为是一个replay为1,且没有缓冲区的SharedFlow,所以新订阅者collect时会先获取一个默认值,构造函数如下:
//MutableStateFlow构造函数
public fun <T> MutableStateFlow(value: T): MutableStateFlow<T> = StateFlowImpl(value ?: NULL)
//MutableStateFlow接口继承了MutableSharedFlow接口
public interface MutableStateFlow<T> : StateFlow<T>, MutableSharedFlow<T> {
public override var value: T
public fun compareAndSet(expect: T, update: T): Boolean
}
StateFlow有自动去重的功能,即如果上游连续发送的value重复时,下游的接收方只会接收第一次的值,后续的重复值不会再接收 可以通过StateFlow.value获取发送的值 stateIn将普通flow转化为StateFlow 普通flow{}可以通过stateIn将普通数据流转换成StateFlow
public fun <T> Flow<T>.stateIn(
scope: CoroutineScope,
started: SharingStarted,
initialValue: T
): StateFlow<T> {
//这里设置的replay是1 及重播给新订阅者的缓存为1
val config = configureSharing(1)
......
}
scope:协程作用域范围
started:控制共享的开始、结束策略。一共有三种,分别为Eagerly、Lazily、WhileSubscribed。
1、SharingStarted.Eagerly, //Eagerly:马上开始,在scope作用域结束时终止
2、SharingStarted.Lazily, //Lazily:当订阅者出现时开始,在scope作用域结束时终止
3、SharingStarted.WhileSubscribed(stopTimeoutMillis: Long = 0,replayExpirationMillis: Long = Long.MAX_VALUE)
其中stopTimeoutMillis:表示最后一个订阅者结束订阅与停止上游流的时间差,默认值为0(立即停止上游流)
replayExpirationMillis:数据重播的超时时间。
initialValue:默认StateFlow的初始值,会发送到下游
使用举例:
//ViewModel中
val flowConvertStateFlow by lazy {
flow {
//转化为StateFlow是 emit()可以是0个或1个 或多个,当是多个时,新订阅者collect只会收到最后一个值(replay为1)
emit("1、flow convert StateFlow")
}
.stateIn(
viewModelScope, //协程作用域范围
SharingStarted.Eagerly, //立即开始
"0、initialValue" // 默认StateFlow的初始值,会发送到下游
).onStart { log("onStart") }
}
//Activity中
mBtnConvertSF.setOnClickListener {
lifecycleScope.launch {
val builder = StringBuilder()
mFlowModel.flowConvertStateFlow.collect {
log(it)
builder.append(it).append("\n")
mTvConvertSF.text = builder.toString()
}
}
}
执行结果:
2021-10-09 16:34:07.180 12394-12394/ E/TTT: onStart 2021-10-09 16:34:07.181 12394-12394/ E/TTT: 0、initialValue 2021-10-09 16:34:07.182 12394-12394/ E/TTT: 1、flow convert StateFlow 注:在UI层使用Lifecycle.repeatOnLifecycle 配合上游的SharingStarted.WhileSubscribed一块使用是一种更安全、性能更好的流收集方式。
StateFlow vs LiveData 在学习LiveData时,我们知道通过LiveData可以让数据被观察,且具备生命周期感知能力,但LiveData的缺点也很明显:
LiveData的接收只能在主线程; LiveData发送数据是一次性买卖,不能多次发送; LiveData发送数据的线程是固定的,不能切换线程,setValue/postValue本质上都是在主线程上发送的。当需要来回切换线程时,LiveData就显得无能为力了。 StateFlow 和 LiveData 具有相似之处。两者都是可观察的数据容器类,并且在应用架构中使用时,两者都遵循相似模式。但两者还是有不同之处的:
StateFlow 需要将初始状态传递给构造函数,而 LiveData 不需要。 当 View 进入 STOPPED 状态时,LiveData.observe() 会自动取消注册使用方,而从 StateFlow 或任何其他数据流收集数据的操作并不会自动停止。如需实现相同的行为,需要从 Lifecycle.repeatOnLifecycle 块收集数据流。 StateFlow、SharedFlow vs Channel Flow底层使用的Channel机制实现,StateFlow、SharedFlow都是一对多的关系,如果上游发送者与下游UI层的订阅者是一对一的关系,可以使用Channel来实现,Channel默认是粘性的。
Channel使用场景:一次性消费场景,比如弹窗,需求是在UI层只弹一次,即使App切到后台再切回来,也不会重复订阅(不会多次弹窗); 如果使用SharedFlow/StateFlow,UI层使用的lifecycle.repeatOnLifecycle、Flow.flowWithLifecycle,则在App切换前后台时,UI层会重复订阅,弹窗事件可能会多次执行,不符合要求。 Channel使用特点:
每个消息只有一个订阅者可以收到,用于一对一的通信 第一个订阅者可以收到collect之前的事件,即粘性事件 Channel使用举例:
//viewModel中
private val _loadingChannel = Channel<Boolean>()
val loadingFlow = _loadingChannel.receiveAsFlow()
private suspend fun loadStart() {
_loadingChannel.send(true)
}
private suspend fun loadFinish() {
_loadingChannel.send(false)
}
//UI层接收Loading信息
mViewModel.loadingFlow.flowWithLifecycle2(this, Lifecycle.State.STARTED) { isShow ->
mStatusViewUtil.showLoadingView(isShow)
}
扩展:suspendCancellableCoroutine & callbackFlow 在新项目或者新需求中,我们可以直接使用协程来替代之前的多线程场景的使用方式,如可以通过withContext(Dispatchers.IO)在协程中来回切换线程且能在线程执行完毕后自动切回当前线程,避免使用接口回调的方式导致逻辑可读性变差。然而,如果我们是在现有项目中开发或者网络框架就是回调方式使用时,没有办法直接使用协程,但是可以通过suspendCancellableCoroutine或callbackFlow将接口回调转化成协程:
suspendCancellableCoroutine等待单次回调API的结果时挂起协程,并将结果返回给调用者;如果需要返回Flow
suspendCancellableCoroutine 使用举例:
//ViewModel中
/**
* suspendCancellableCoroutine将回调转化为协程使用
*/
suspend fun suspendCancelableData(): String {
return try {
getSccInfo()
} catch (e: Exception) {
"error: ${e.message}"
}
}
/**
* suspendCancellableCoroutine将回调转化为协程使用
*/
private suspend fun getSccInfo(): String = suspendCancellableCoroutine { continuation ->
val callback = object : ICallBack {
override fun onSuccess(sucStr: String?) {
//1、返回结果 将结果赋值给getSccInfo()挂起函数的返回值
//2、如果调用了continuation.cancel(),resume()的结果将不会返回了,因为协程取消了
continuation.resume(sucStr ?: "empty")
}
override fun onError(error: Exception) {
//这里会将异常抛给上层 需要上层进行处理
continuation.resumeWithException(error)
}
}
continuation.invokeOnCancellation {
//协程取消时调用,可以在这里进行解注册
log("invokeOnCancellation")
}
//模拟网络请求 此时协程被suspendCancellableCoroutine挂起,直到触发回调
Thread {
Thread.sleep(500)
//模拟Server返回数据
callback.onSuccess("getServerInfo")
//模拟抛异常
//callback.onError(IllegalArgumentException("server error"))
}.start()
//模拟取消协程
//continuation.cancel()
}
//Activity中
mBtnScc.setOnClickListener {
lifecycleScope.launch {
val result = mFlowModel.suspendCancelableData()
log(result)
}
}
执行结果:
2021-10-11 13:31:41.384 24114-24114/ E/TTT: getServerInfo suspendCancellableCoroutine声明了作用域,并且传入一个CancellableContinuation参数,它可以调用resume、resumeWithException来处理对应的成功、失败回调,还可以调用cancel()方法取消协程的执行(抛出CancellationException异常,但程序不会崩溃,当然也可以通过catch抓住该异常进行处理)。
上面例子中,当开始执行时会将suspendCancellableCoroutine作用域内协程挂起,如果成功返回数据,会回调continuation.resume()方法将结果返回;如果出现异常,会回调continuation.resumeWithException()将异常抛到上层。这样整个函数处理完后,上层会从挂起点恢复并继续往下执行。
callbackFlow
callbackFlow相对于suspendCancellableCoroutine,对接口回调封装以后返回的是Flow数据流,后续就可以对数据流进行一系列操作。
callbackFlow中的几个重要方法:
trySend/offer:在接口回调中使用,用于上游发射数据,类似于flow{}中的emit(),kotlin 1.5.0以下使用offer,1.5.0以上推荐使用trySend() awaitClose:写在最后,这是一个挂起函数, 当 flow 被关闭的时候 block 中的代码会被执行 可以在这里取消接口的注册等。 使用举例,比如当前有个场景:去某个地方,需要先对目的地进行搜索,再出发到达目的地,假设搜索、到达目的地两个行为都是使用回调来执行的,我们现在使用callbackFlow对他们进行修改:
ViewModel中,搜索目的地:
fun getSearchCallbackFlow(): Flow<Boolean> = callbackFlow {
val callback = object : ICallBack {
override fun onSuccess(sucStr: String?) {
//搜索目的地成功
trySend(true)
}
override fun onError(error: Exception) {
//搜索目的地失败
trySend(false)
}
}
//模拟网络请求
Thread {
Thread.sleep(500)
//模拟Server返回数据
callback.onSuccess("getServerInfo")
}.start()
//这是一个挂起函数, 当 flow 被关闭的时候 block 中的代码会被执行 可以在这里取消接口的注册等
awaitClose { log("awaitClose") }
}
ViewModel中,前往目的地:
fun goDesCallbackFlow(isSuc: Boolean): Flow<String?> = callbackFlow {
val callback = object : ICallBack {
override fun onSuccess(sucStr: String?) {
trySend(sucStr)
}
override fun onError(error: Exception) {
trySend(error.message)
}
}
//模拟网络请求
Thread {
Thread.sleep(500)
if (isSuc) {
//到达目的地
callback.onSuccess("arrive at the destination")
} else {
//发生了错误
callback.onError(IllegalArgumentException("Not at destination"))
}
}.start()
awaitClose { log("awaitClose") }
}
Activity中,使用Flow.flatMapConcat对两者进行整合:
mBtnCallbackFlow.setOnClickListener {
lifecycleScope.launch {
//将两个callbackFlow串联起来 先搜索目的地,然后到达目的地
mFlowModel.getSearchCallbackFlow()
.flatMapConcat {
mFlowModel.goDesCallbackFlow(it)
}.collect {
mTvCallbackFlow.text = it ?: "error"
}
}
}
执行结果:
2021-10-11 19:13:36.528 10233-10233/ E/TTT: arrive at the destination 以下结论摘自官网:
与 flow 构建器不同,callbackFlow 允许通过 send 函数从不同 CoroutineContext 发出值,或者通过 offer/trySend 函数在协程外发出值。 在协程内部,callbackFlow 会使用通道,它在概念上与阻塞队列非常相似。通道都有容量配置,限定了可缓冲元素数的上限。在 callbackFlow 中所创建通道的默认容量为 64 个元素。当您尝试向完整通道添加新元素时,send 会将数据提供方挂起,直到新元素有空间为止,而 offer 不会将相关元素添加到通道中,并会立即返回 false。